私たちが普段何気なく利用している「検索サイト」が、どのような仕組みで検索結果を生成しているのかを知ることは、企業のWEB担当者にとって重要なことです。今回はWEB担当者が最低限知っておかなければならない検索エンジンの仕組みについて紹介いたします。
私たちが普段何気なく利用している「検索サイト」が、どのような仕組みで検索結果を生成しているのかを知ることは、企業のWEB担当者にとって重要なことです。今回はWEB担当者が最低限知っておかなければならない検索エンジンの仕組みについて紹介いたします。
3つの主要な検索エンジン
 日本で利用されている主な検索エンジンサービスは、Google、Yahoo! JAPAN、Bingの3つです。これらはそれぞれ別の会社が運営していますが、Yahoo! JAPANは2012年からGoogleのサーバーを利用しているため、両社の検索結果は非常に似ています(Yahoo! JAPANはGoogleから提供されるデータに+独自の処理を追加しているため、非常に似てはいても異なる検索結果となっています)。
日本で利用されている主な検索エンジンサービスは、Google、Yahoo! JAPAN、Bingの3つです。これらはそれぞれ別の会社が運営していますが、Yahoo! JAPANは2012年からGoogleのサーバーを利用しているため、両社の検索結果は非常に似ています(Yahoo! JAPANはGoogleから提供されるデータに+独自の処理を追加しているため、非常に似てはいても異なる検索結果となっています)。
また検索サービスの日本国内でのシェアは下記のようになっています。
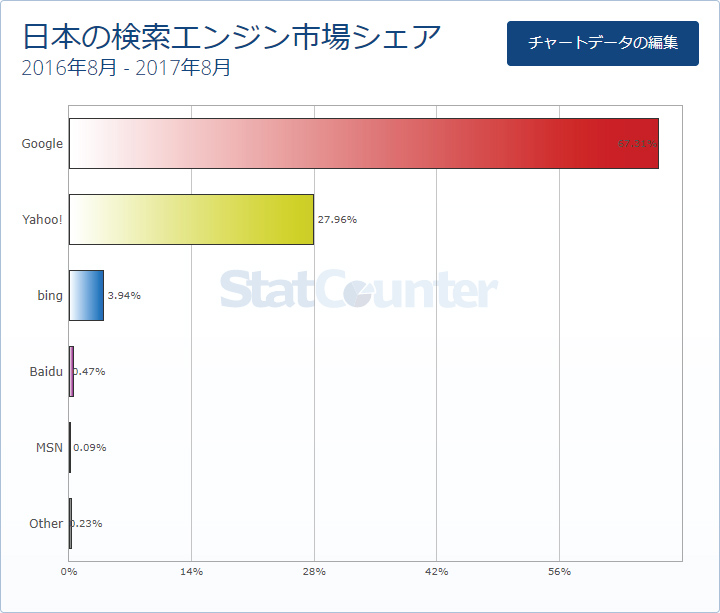 グラフを見てもらえればわかる通り、検索エンジン対策は実質Google向けの対策さえ行えば良いということになります(あくまでも一般的なサイトの話です)。
グラフを見てもらえればわかる通り、検索エンジン対策は実質Google向けの対策さえ行えば良いということになります(あくまでも一般的なサイトの話です)。
覚えるべき検索エンジンの仕組みは3つ
01.検索エンジンのクローラーがWEB上のデータを収集する
検索サービスを提供する会社は「クローラー」と呼ばれるシステムを持っています。このクローラーは、WEB上に展開されるあらゆる情報(WEBページ)を休みなく、チェックしています。このチェック作業をクローリングといいます。
02.収集されたデータは検索データベース(インデックス)に格納される
クローラーが収集した情報(WEBページ)は、インデクサーと呼ばれるシステムによって、そのページが「どんなテーマを扱うページなのか」「どんなキーワードを含んでいるか」「どこからリンクを受けているのか」などの基準で、細かく分析され、データベースに格納されます。この処理をインデックスと呼びます。
03.ユーザーから検索が送られると、アルゴリズムに基づいてインデックスされているWEBページのスコアリングが行われ、点数の高い順に検索結果が出力される
ユーザーが検索窓にキーワードを入力すると、検索エンジンはそのユーザーの検索目的を予測し、瞬時にインデックスされているデータの中から、目的が達成される可能性が高いページをリストアップして、ランキング形式で表示します。
かなりざっくりとした説明になっていますが、このような流れで私たちの作るWEBページはランク付けされ、検索結果に表示されているのです。そして、以上がWEB担当者が最低限理解しておくべき検索エンジンの仕組みになります。検索エンジンの仕組みを理解することは、何らかの問題が発生したときに、問題の特定に役立ちますし、また、取り組むべき行動を決定するのに役立ちますので、この機会にぜひ覚えておいてください。